Video-based lesson. Pedagogical focus on reinforcing knowledge the learner already encountered. User prompt: Conrad shares a story using regular and irregular verbs in the past (e.g., “We danced,” “I met someone”). The student identifies verb forms and practices choosing correct past tense options in context.
Chat-based lesson. Pedagogical focus on reviewing and reinforcing vocabulary by practicing how to pronounce it correctly. User prompt: Common medical everyday expressions
Video-based lesson. Pedagogical focus on reviewing vocabulary in context and reinforcing the grammar patterns that support correct usage. User prompt: teacher shares snapshots of her dance group and describes their activities using imperatives: “Come early to warm up.” / “Don’t forget water.” Each clip is followed by a gap-fill MCQ like: “What should they bring?” [shoes / water / food]. Total: 5–6.”,
Context
Our mission at BeConfident Labs is to improve global education by creating AI that matters. This work embodies the contribution of three proudly Brazilian researchers, two master’s students in Artificial Intelligence at Stanford University and one master’s student in Language Learning, united by a shared commitment to advancing AI for Education in Latin America.
BeConfident Labs is the research arm of BeConfident Corp., creator of the BeConfident App. Launched in early 2023, the app now serves over 1.8 million learners across Latin America [1]. It uses AI-powered digital twins to teach English through a multi-platform experience, integrating seamlessly with WhatsApp and a standalone mobile application. Currently designed for native Portuguese and Spanish speakers, the platform enables voice and text messaging, instant feedback on pronunciation, grammar, and fluency, multi-persona conversations, and real-time voice calls.
BeConfident App is a powerful case study in the democratization of education. Its core users are busy, middle-aged professionals who once believed learning opportunities had passed them by—people with limited time, high demands, and a deep apprehension about practicing English. The platform restores access to education through approachable, confidence-building AI interactions.
Second Language Acquisition
Our work is grounded in Second Language Acquisition (SLA) research, the field that studies how people learn additional languages. A central distinction in SLA is between productive and receptive skills [3][4][5]:
Productive skills (speaking and writing) involve actively producing language and depend on output, feedback, and interaction to develop accuracy, fluency, and communicative confidence. [4][6][5]
Receptive skills (listening and reading) develop through comprehension of meaningful input, enabling learners to internalize vocabulary, grammar, and discourse patterns that later support productive use. [3]
In the BeConfident App, productive skills are cultivated through real-time voice and text conversations with AI tutors, allowing learners to practice speaking naturally and receive immediate, personalized feedback. However, SLA research highlights that receptive skills are equally essential: they introduce new vocabulary, grammar, and contextual understanding that later fuel productive expression.
Recognizing this need, the BeConfident team took the initiative nearly a year ago to extend its conversational model by developing mini English lessons designed specifically to strengthen receptive skills. These lessons integrate graded listening and reading tasks, contextualized examples, and adaptive sequencing, replicating the structured input traditionally provided in classroom instruction, while preserving the affordances given by AI technologies.
Scaling pedagogical quality
The challenge was production at scale. To serve 1.8 million learners, we needed thousands of lessons spanning nine formats, six proficiency levels, dozens of modules, and hundreds of contexts—far beyond what manual authoring could produce. Yet language learning demands exceptional pedagogical quality: a well-timed correction can accelerate learning; the same correction delivered at the wrong moment can damage confidence. Complexity must be calibrated to avoid cognitive overload while promoting growth.
This created a fundamental tension: we needed AI to generate content at scale, but that AI would need to internalize when feedback serves a purpose and how different interaction patterns support different learning objectives. Before we could attempt AI-assisted generation, we needed to formalize what “pedagogically sound” meant in concrete, measurable terms.
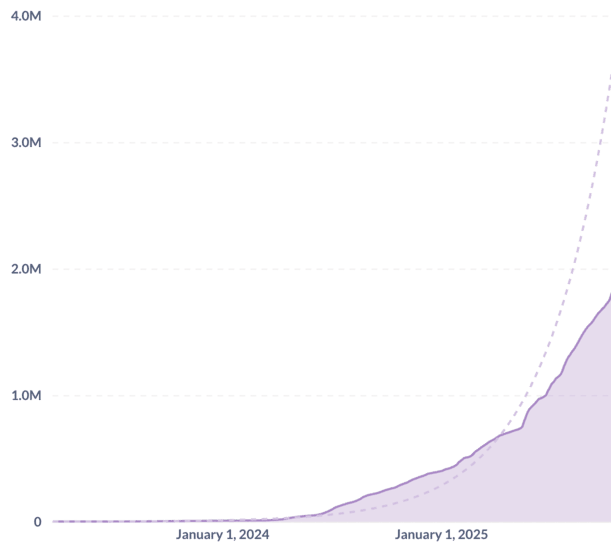
Cumulative user base of the BeConfident App, surpassing 1.8 million users by October 2025. The trajectory follows an exponential growth tendency.
Curricular Architecture
To operationalize these SLA principle at scale, we established a pedagogical hierarchy that guides all BeConfident content:
Lessons are the atomic unit: a single learning experience (e.g., introducing past tense through a narrative)
Modules group 4-5 related lessons around a thematic or structural focus (e.g., “Food and Feelings”)
Units organize multiple modules for a specific proficiency level (e.g., A1, B1, C1)
This hierarchy is pedagogically essential. Content appropriate for an A0 learner looks fundamentally different from B1 content—not just in vocabulary or grammatical complexity, but in interaction patterns, cognitive load, and scaffolding strategies. The model needed to understand this contextual positioning to generate coherently within a curricular sequence. Our golden dataset had also revealed another critical abstraction: lesson formats. Not all lessons share the same structure. We identified distinct formats, each with its own interaction signature.
These formats aren’t purely cosmetic. They represent fundamentally different lesson architectures with distinct interaction patterns, evaluation strategies, and content requirements. For example, A VideoIntroduceGrammar lesson follows a presentation→guided-practice→feedback pattern, while VideoConsolidateLexis emphasizes repetition and varied contextualization.
Our approach to generating high-quality, on-demand lessons using AI capabilities followed a three-phase strategy.
Phase 1: Building the Golden Dataset
Our first challenge was establishing what “high-quality” actually looked like in concrete, measurable terms. Before we could train a model to generate lessons, we needed a Golden Dataset: a curated dataset with reference-standard (ground-truth) labels used as the benchmark for training/evaluating models [18]. In our context, this meant creating exemplar lessons that would serve as both a quality benchmark and a foundation for understanding what pedagogical excellence meant in practice.
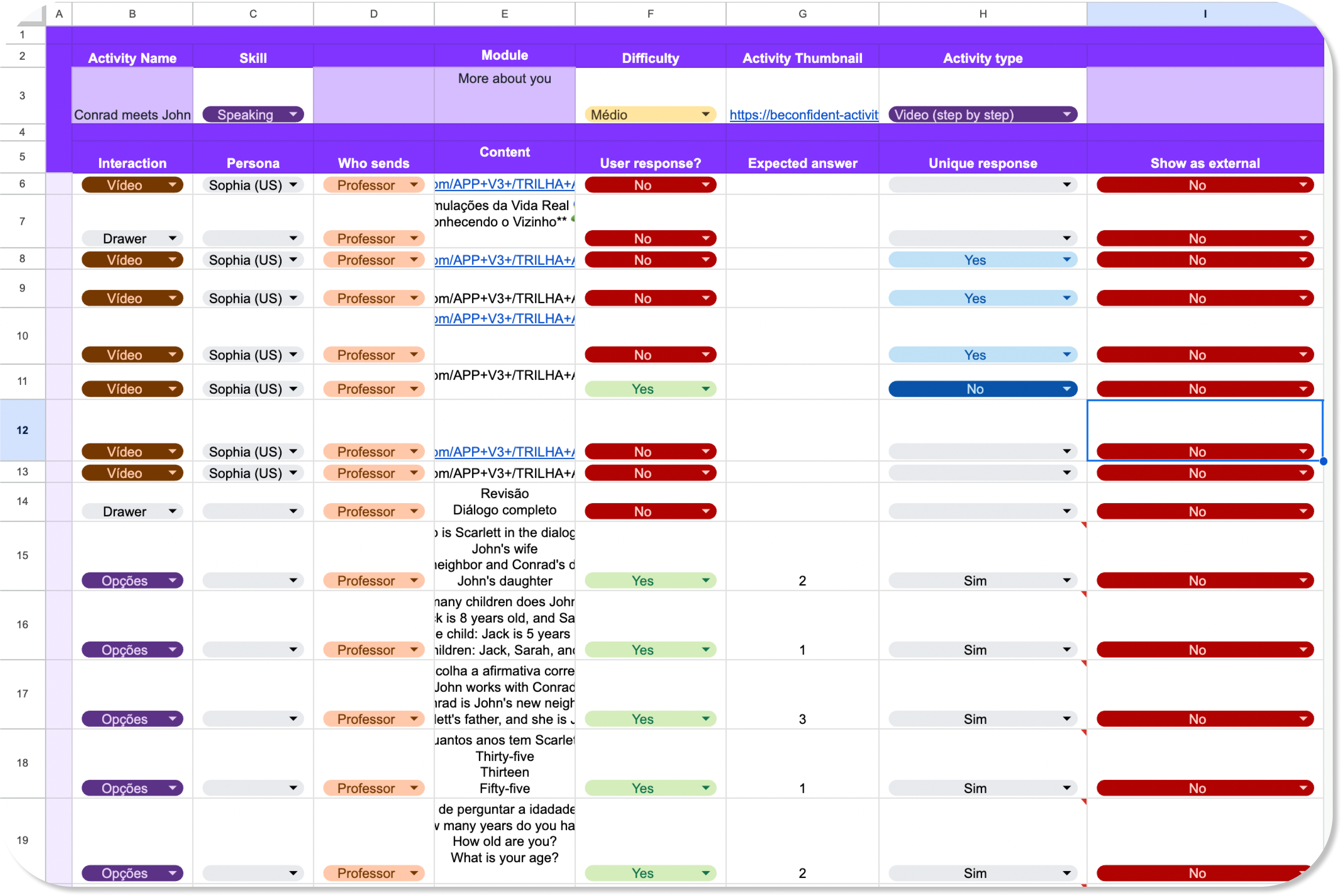
Example of a manually authored English lesson in a Google Sheet. Each row represents one learner interaction.
Language learning specialists crafted activities as explicit interaction programs in structured spreadsheets. Each row represented one interaction turn with fields specifying: interaction type (video, options, text input, audio), persona, content, user response requirements, expected answers, conditional logic, and display rules. A typical lesson comprised 30-50 such rows, essentially encoding the activity as a finite state machine with conditional transitions.
The resulting golden dataset (hundreds of activities across proficiency levels) served as: (1) training data for supervised fine-tuning, (2) reference standard for reward function design, (3) quality benchmark for evaluating generated content, and (4) pattern corpus revealing the structure of effective pedagogy. But it also established the fundamental constraint: human authoring at this level of specification couldn’t scale to cover the combinatorial space of learning contexts we required. The golden dataset had formalized quality. Now we needed to preserve it while increasing production capacity by orders of magnitude.
It was time for the Phase 2.
Phase 2: Scaling with Structured Generation
Escaping AI Slop
The obvious next step was AI-assisted authoring. Like many in our field, we were excited by the potential of large language models to accelerate content creation. But we were also wary of what has come to be called AI slop—the flood of low-quality, generic content that prioritizes volume over value. [17]
In language learning, slop isn’t just annoying; it’s pedagogically harmful. A poorly timed correction can damage confidence. An inappropriate difficulty jump can cause cognitive overload [7]. A generic, context-free explanation can reinforce misconceptions. Our challenge wasn’t simply generating more content, it was generating content that maintained the careful orchestration of feedback, pacing, and adaptation that characterized our hand-authored lessons.
This led us to a key insight: we needed models aligned not just with the surface form of good lessons, but with the underlying pedagogical principles that made them effective. We needed the model to learn what makes feedback timely, what makes a difficulty progression appropriate, what makes an explanation clear within a specific learning context. The question became: how do we train for principles rather than patterns?
Structured Generation at Scale
With our golden dataset established, we moved to Phase 2: using existing large language models to generate lessons at scale through few-shot prompting. The approach leveraged our carefully curated examples, for each lesson format in our golden dataset, we selected representative exemplars to perform Few-Shot Prompting.
We built a system around structured outputs: the model received a JSON schema corresponding to our spreadsheet format and returned fully specified lesson objects. Each output populated dozens of fields per interaction. [19]
But generating the lesson structure was only the first step. Each lesson required additional assets: AI-generated videos of our digital teacher personas, audio files for pronunciation exercises, visual materials for vocabulary presentation. We built an orchestration pipeline that took the initial JSON output, made parallel requests to our video and audio generation services, and returned the completed lesson object with all media URLs properly populated. This pipeline became an internal API endpoint, specify parameters, receive a production-ready lesson that could be deployed directly into our app for testing.
Parametric Generation
The API required explicit specification:
Format: Structural type (VideoIntroduceGrammar, VideoConsolidateLexis, etc.
Module context: Thematic scope and learning objectives within broader module
Proficiency level: CEFR calibration (A0-C1) for linguistic complexity. [2]
Difficulty: Fine-grained adjustment within proficiency band
Teacher persona: Digital twin instructor identity with distinct biographical, conversational, pedagogical, and phonetic characteristics
Combined with format-specific few-shot examples, these parameters enabled generation that maintained contextual coherence and persona consistency.
Activity Editor
Our first API endpoint immediately allowed us to produce thousands of lessons, but with the risk of producing the already aforementioned AI slop. To make sure our classes were of the highest quality, we decided to go with a human-in-the-loop approach.
That’s how we built the Activity Editor: a WYSIWYG back-office platform for our language learning specialists [15]. The interface enabled rapid refinement: visualize lesson as learners would experience it, modify any interaction in place, reorder sequence, adjust difficulty parameters, push to production.

Walkthrough of our Activity Editor backoffice platform. This allows Language Learning Specialists to quickly generate activities and edit them, allowing our throughput to be greatly accelerated
The result: we produced thousands of lessons across proficiency levels, formats, and modules in a matter of months. The throughput increase was dramatic. The quality remained high. We’d avoided the AI slop problem through careful review while preserving the scaling benefits of generation.
This human-in-the-loop architecture was crucial. It let us leverage AI’s generation speed while maintaining our quality bar. Specialists weren’t authoring from scratch anymore. They were refining, correcting edge cases, ensuring pedagogical coherence, and catching the subtle issues that distinguished good lessons from great ones. A task that once took 4-6 hours now took ~15 minutes of focused review and refinement.
More importantly, though, is that we began to recognize a pattern: over thousands of lessons, the small modificationsmade by the specialists accumulated into a rich signal. We were inadvertently creating a representation learning loop [16].
This realization suggested a different approach: what if we could train directly on these refinements? Could we build a model that learned not just from our golden dataset, but from the pattern of improvements embedded in our diffs? Such a training loop wouldn’t just reduce human review burden, it would continuously improve the quality of generated classes by learning from the very feedback we were already collecting.
That insight led us to our final Phase.
Phase 3: Confiante G1
Phase 2 succeeded in scaling production, but the 15-minute review requirement per lesson remained. More critically, few-shot prompting couldn’t learn from corrections. Each generation started fresh with static examples, unable to internalize the patterns our specialists had refined across thousands of lessons. To learn from our accumulated training signal, we needed fine-tuning: updating the model’s parameters so lessons learned would persist across all future generations.
But what kind of fine-tuning? We had two options.
From Imitation to Optimization
Supervised fine-tuning (SFT) teaches models to replicate reference outputs. Show it excellent A2-level vocabulary lessons, and it learns statistical patterns: typical sentence lengths, common grammatical structures, vocabulary density. The model becomes adept at producing content that resembles training examples.
But resemblance isn’t understanding. SFT learns surface patterns rather than the pedagogical principles that generate them. It doesn’t internalize why feedback placement matters or when to adjust difficulty. More critically, it requires explicit examples for every scenario. Want the model to handle feedback for past progressive errors in Brazilian Portuguese learners? You need training examples of that specific case. The data requirements scale poorly with the combinatorial explosion of contexts, proficiency levels, error types, and learning objectives.
Reinforcement fine-tuning (RFT) inverts this paradigm. Instead of imitating examples, the model learns to optimize for outcomes [10][11]. We provide a reward function (a computational measure of lesson quality) and through iterative refinement, the model discovers generation strategies that maximize reward.
This approach offers critical advantages in both efficiency and capability:
Sample Efficiency: A single well-designed reward component can replace thousands of curated examples. If the reward function penalizes verbosity, the model learns conciseness across all contexts—not just those represented in training data. The model generalizes from principles encoded in the reward function, not from pattern-matching against finite examples. This becomes especially powerful in domains like education where the space of possible scenarios is effectively infinite.
Composite Objectives: Some pedagogical qualities are far easier to evaluate than to demonstrate. Consider “appropriate cognitive load”—the subjective sense that a lesson challenges without overwhelming. This is difficult to convey through example lessons but can be estimated by measuring grammatical complexity, vocabulary density, number of new concepts, and interaction patterns. The reward function can directly optimize for this composite measure, capturing qualities that would require massive datasets to teach through imitation alone.
Principled Generalization: Because RFT trains models to maximize reward rather than match patterns, it naturally handles edge cases and novel combinations in ways that SFT struggles with. The model learns the underlying structure of what makes content pedagogically sound, then applies those learned principles to new contexts.
The Critical Role of Reward Design
This power comes with a critical requirement: the reward function must accurately capture what “good” means in your domain. The model will optimize for whatever you measure, so measurement must align precisely with intended outcomes. A poorly designed reward can lead to reward hacking—the model finding loopholes that maximize the metric without achieving the goal [12][13].
This is where OpenAI’s guidance on RFT becomes particularly relevant. Their documentation emphasizes that “RFT works best with unambiguous tasks. Check whether qualified human experts agree on the answers. If conscientious experts working independently (with access only to the same instructions and information as the model) do not converge on the same answers, the task may be too ambiguous and may benefit from revision or reframing.” [10]
This requirement posed a significant challenge for our use case. Pedagogical quality is inherently somewhat subjective, different experienced instructors might disagree on whether a particular feedback moment is optimally timed, or whether a lesson progression is ideally paced. How could we create unambiguous reward signals in a domain with inherent subjectivity?
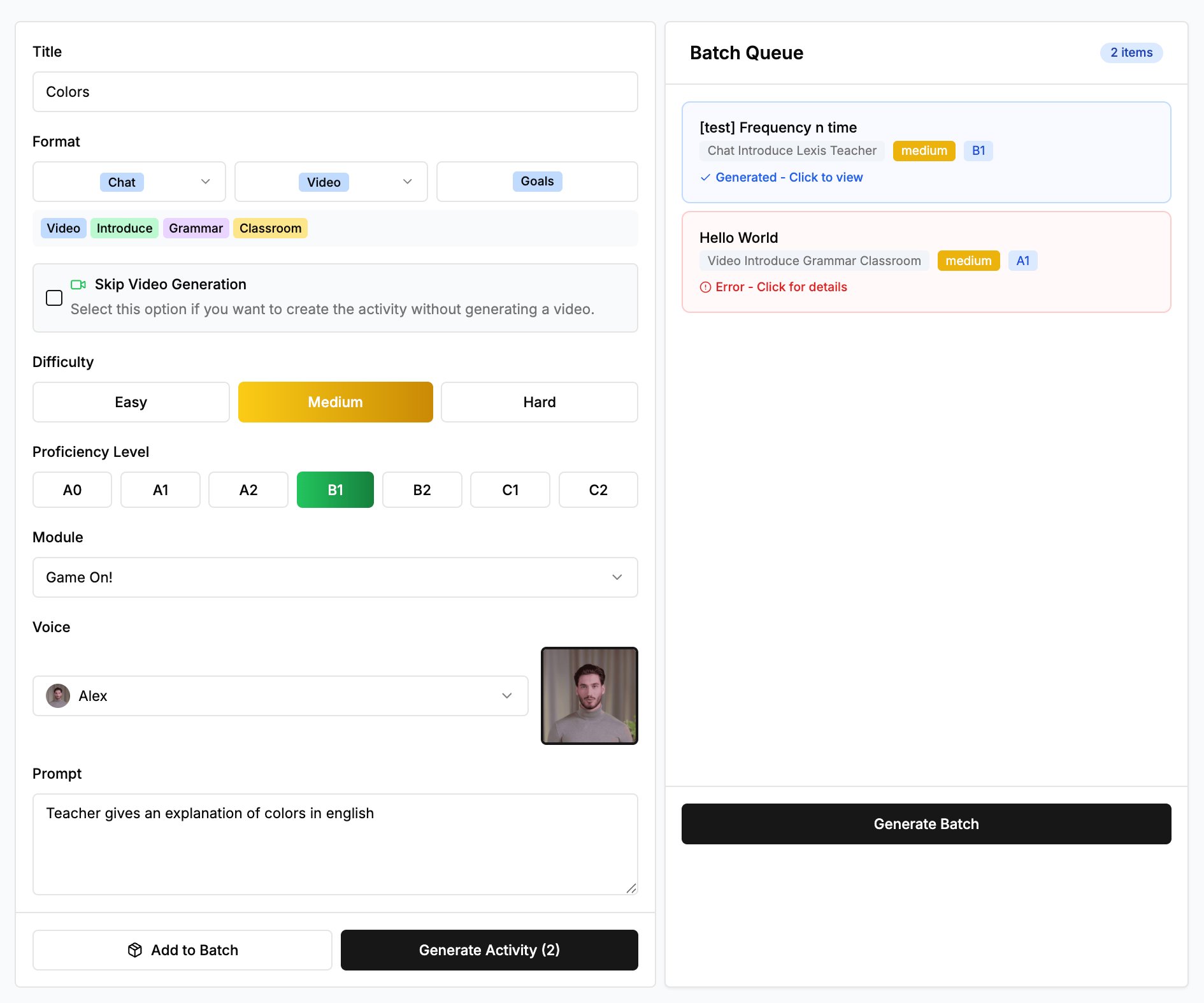
Creation process of a new lesson in our Activity Editor using Confiante G1.
Phase 2 produced thousands of lessons and, more importantly, a rich training signal: the diff between the model’s raw outputs and expert-refined versions. This insight led us to a pivotal decision: to train our own model on those diffs, combining them with our language experts’ intuitions distilled into a reward function.
Yet we soon realized that our nine lesson formats posed a major challenge: each demanded its own evaluation logic. Our nine lesson formats presented a fundamental problem for reward design. A VideoIntroduceGrammar lesson requires assessment on scaffolding progression and concept clarity. A ChatTestPronunciation lesson requires phonetic targeting. A VideoConsolidateLexis lesson requires repetition patterns and contextual variety. And so on. These formats exist precisely because different learning objectives demand different instructional approaches.
Cluster-Based Rubrics
An obvious solution was to train n separate models, one per lesson format with its own rubric. But this quickly became unmanageable. Each model demanded separate deployments, monitoring, and versioning. A/B testing across formats required coordinating nine experiments at once, and every update multiplied rollout and rollback complexity. At our scale (thousands of lessons generated daily) this operational burden was prohibitive.
A single model with all rubrics, however, led to signal distortion. Applying every rubric to every output created contradictory gradients. For example, a pronunciation test scored on grammar rubrics would be unfairly penalized for missing irrelevant features, pushing the model away from the correct structure.
To address this, we developed a new training framework we call cluster-based rubrics. The key idea: treat each format as an evaluation cluster with format-specific rubrics, then use deterministic masking to filter irrelevant criteria during scoring. (see [20] for an analogous approach related to mixture-of-experts)
The architecture comprises three grader types and a last reward aggregator function:
Formatting Graders (deterministic) validate conditional logic in output values—checking that interactions requiring replies have corresponding answers, that asset URLs are properly formatted, and that field values satisfy domain constraints. Returns:
Note that JSON schema compliance is enforced separately via OpenAI’s structured outputs; the Formatting Grader validates semantic correctness beyond schema.
Rubric Graders (LLM-based or deterministic graders) score specific pedagogical dimensions. Each returning score in the Likert scale:
Indicator Graders (deterministic) implement cluster membership logic: for format f and rubric r, the indicator returns:
The Aggregator combines scores via:
where is the final score, is the format validation score, is the format weight, is the total number of rubrics, is the indicator for rubric , is the rubric weight, and is the rubric score.
The weights () are hyperparameters that provide flexibility to emphasize certain pedagogical dimensions over others. For instance, “Scaffolding Quality” might warrant higher weight in VideoIntroduceGrammar lessons, while “Repetition Balance” might be more critical for VideoConsolidateLexis. This flexibility allows the reward function to reflect domain expertise about which criteria matter most for each format.
For Confiante G1, we set rubric weights to a homogeneous default:
For Confiante G1, we set rubric weights to a homogeneous default:
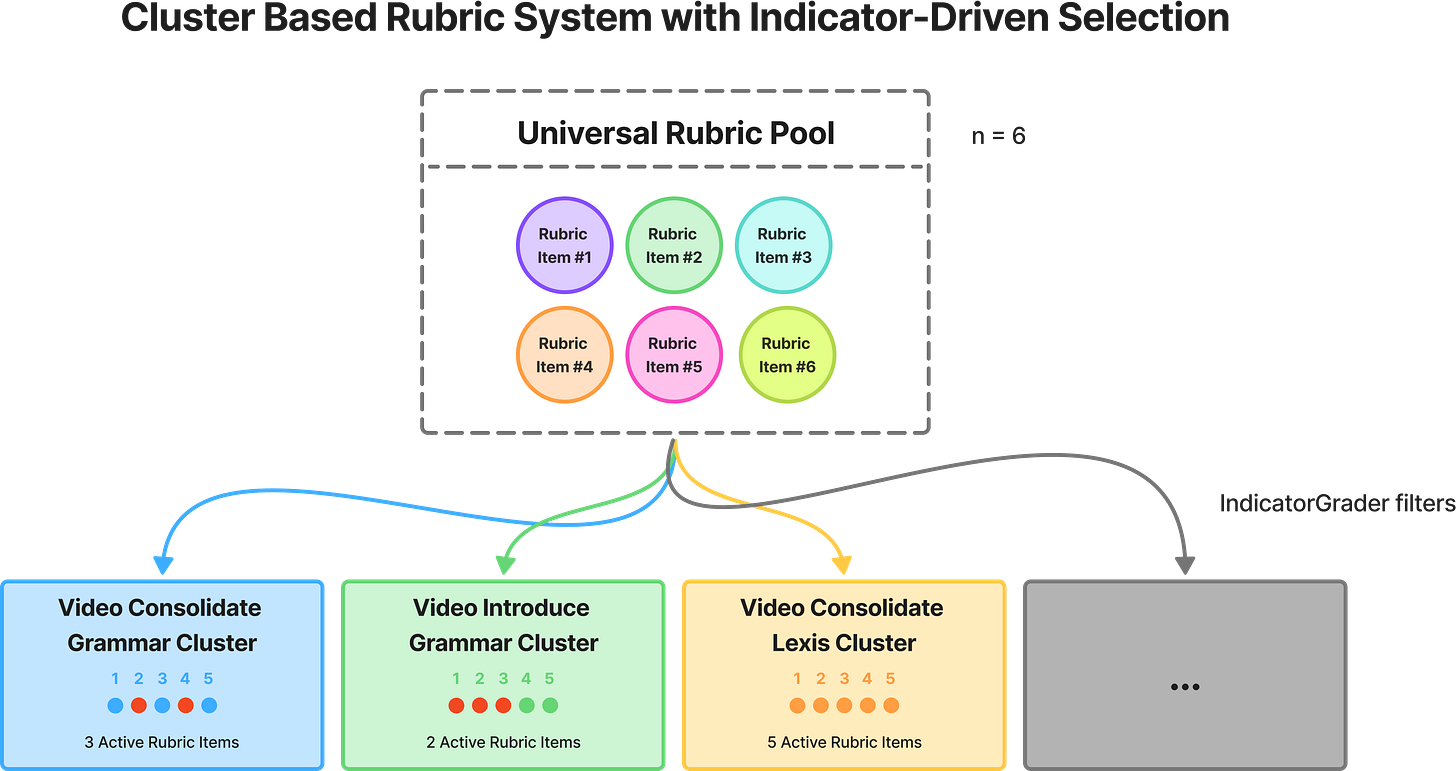
Cluster-based rubric architecture. A universal rubric pool (n=6 shown) is filtered by deterministic IndicatorGraders for each format cluster, selecting only applicable rubrics (colored circles) while masking irrelevant ones, enabling format-specific evaluation within a unified reward function.
RFTKit
Implementing this architecture required a framework for composing graders, defining cluster mappings, and exporting to OpenAI’s RFT API format. We developed RFTKit, a Pydantic-based library that handles the mechanics of cluster-based reward functions. The library provides base abstractions for each grader type, enforces type safety through validation, and exports configurations directly to OpenAI’s RFT API. During Confiante G1 development, this enabled rapid iteration. We could then modify rubric definitions, adjust cluster mappings, and redeploy reward functions without manual JSON configuration.
We open-sourced RFTKit as a domain-agnostic library. While we developed it for education-specific rubrics, the cluster-based paradigm applies to any multi-format evaluation problem: code generation across programming languages (where syntax, style, and performance criteria vary by language), creative writing across genres (where different genres demand different stylistic criteria), or structured data generation across schemas. By releasing this framework, we aim to enable research in reward function design for complex, multi-format domains beyond language education.
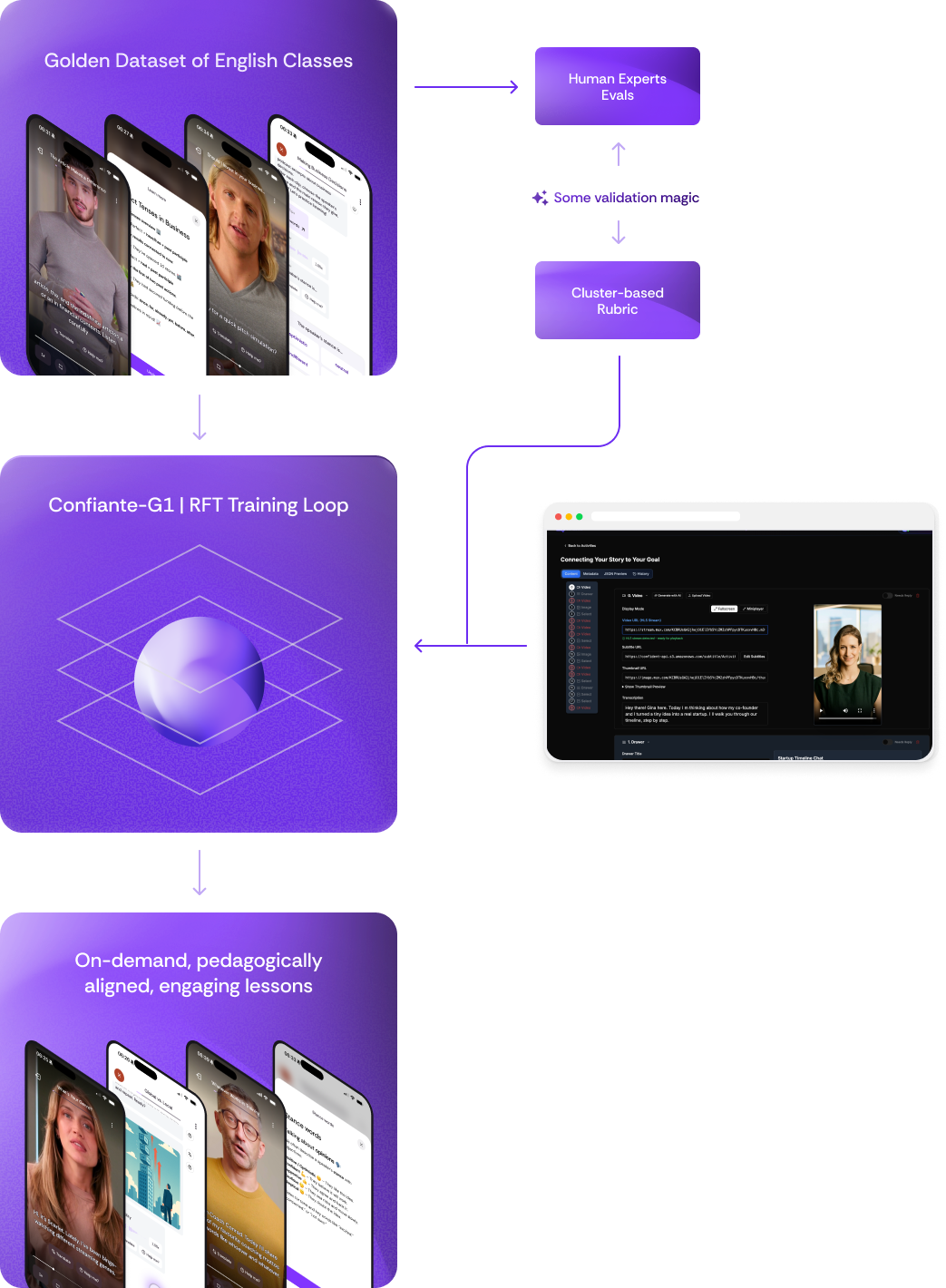
Confiante G1 diagram.
Results
We aggregated individual rubric items into three broader evaluation clusters, Pedagogical Alignment, Fun Pacing, and Format Correctness. The specific rubric items are not disclosed, since they represent proprietary constructs that emerged from our iterative alignment and evaluation process.
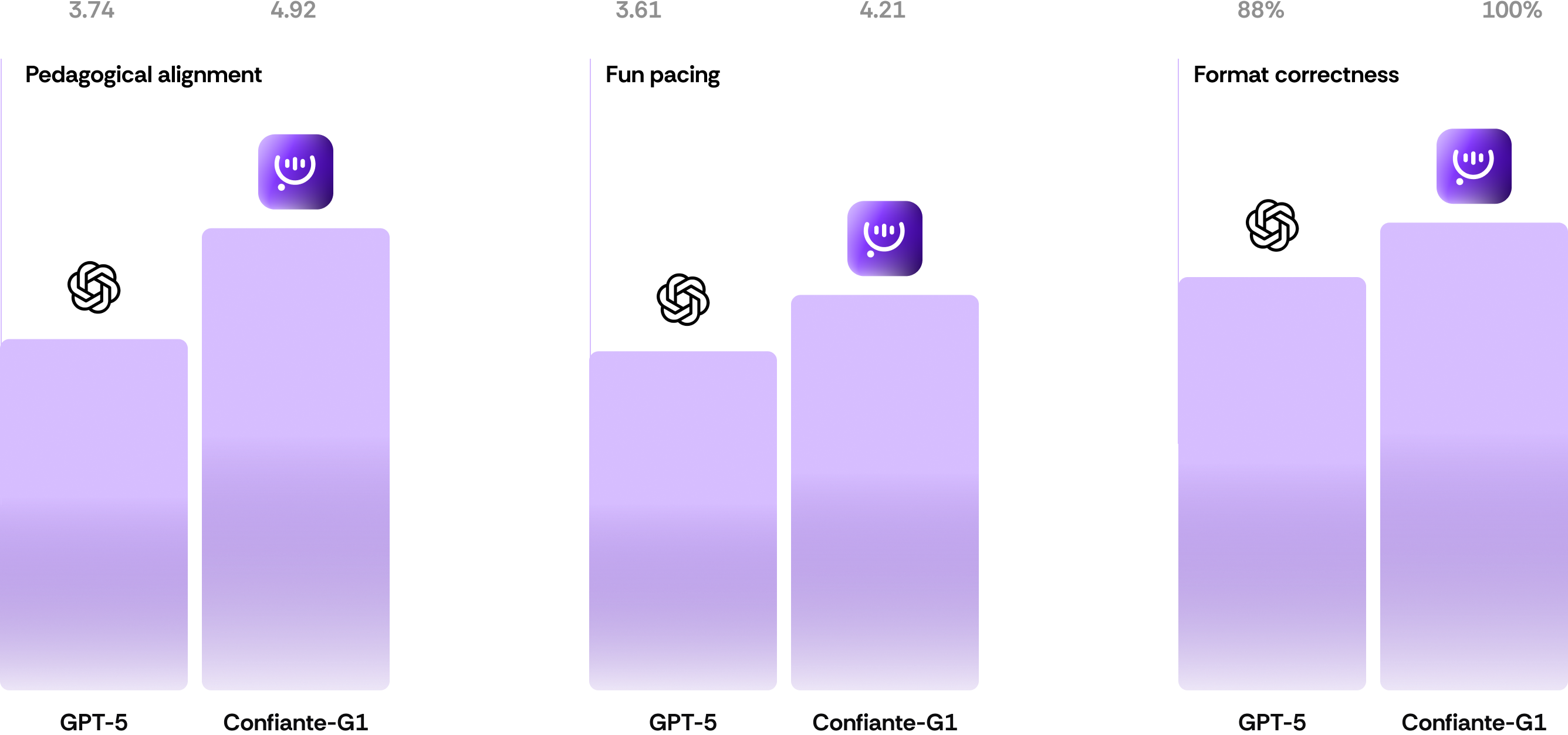
Evaluation of 20k English lessons across rubric clusters. The first two metrics report the average scores (Likert 1–5) for Pedagogical Alignment and Fun Pacing; the third reports Format Correctness as accuracy (%).
Conclusion
We created Confiante G1, a foundation model for English language instruction. By using reinforcement fine-tuning with a novel cluster-based rubric system, we achieved pedagogically sound lesson generation at scale. The model learned to optimize for underlying pedagogical principles rather than surface patterns, enabling it to generalize across the combinatorial space of proficiency levels, lesson formats, and learning contexts.
Our approach demonstrates that with careful reward function design, AI models can be aligned to domain-specific quality standards even in subjective fields like education. The cluster-based rubric framework we developed addresses a fundamental challenge in multi-format training: how to provide format-specific evaluation without the operational burden of maintaining separate models.
Classes generated by Confiante G1 are available on BeConfident App, serving our 1.8 million learners across Latin America.
Author Contributions Statement
Gui Dávid: Conceptualization; project leadership (Phases 2–3); design and implementation of the Activity Editor; ML training and reinforcement fine-tuning; co-design and co-implementation of the cluster-based rubric and RFTKit; writing, original draft and revisions.
Artur B. Carneiro: Contributions focused exclusively on the cluster-based rubric and RFTKit (jointly with Gui): architecture, implementation, documentation, and open-source release; writing, methods related to these components.
Aline Coutinho: Phase 1 leadership (SLA grounding); Phase 2 lesson quality assurance. curriculum and proficiency architecture; rubric definition and validation; evaluation protocols;
BeConfident App Team: Technology and productization: design (Melanie Bruckner); product (Felipe Silva, CPO); platform/API engineering (Felipe Tiozo, CTO) and the engineering team; inference infrastructure embedded into the BeConfident App and production deployment.
References
[1] BeConfident App. https://beconfident.app
[2] Council of Europe. CEFR Companion Volume with New Descriptors (2020). PDF: https://www.ecml.at/Portals/1/5MTP/CEFR_Companion_Volume_with_new_descriptors.pdf
[3] Krashen, S. D. (1982). Principles and Practice in Second Language Acquisition. (Book)
[4] Swain, M. (2005). The Output Hypothesis: Theory and Research. In Hinkel, E. (Ed.), Handbook of Research in Second Language Teaching and Learning. (Chapter)
[5] Long, M. H. (1996). The role of the linguistic environment in second language acquisition. In Ritchie & Bhatia (Eds.), Handbook of SLA. (Chapter)
[6] Lyster, R., & Ranta, L. (1997). Corrective Feedback and Learner Uptake. Studies in Second Language Acquisition, 19(1), 37–66. (Univ. of Alberta copy) https://era.library.ualberta.ca/items/df1641ab-c2db-4ec8-a744-6de01fb92387/view/cdfbe668-3aaf-44f9-82e7-56fa4002cb09/Corrective-20feedback-20and-20learner-20uptake.pdf
[7] Sweller, J. (2011). Cognitive Load Theory. Educational Psychology Review, 23, 261–266. https://doi.org/10.1007/s10648-010-9135-1
[8] Brown, T. B., et al. (2020). Language Models are Few-Shot Learners. NeurIPS 2020. arXiv:2005.14165 https://arxiv.org/abs/2005.14165
[10] OpenAI. Reinforcement Fine-Tuning (RFT) Guide & API docs. https://platform.openai.com/docs/guides/reinforcement-fine-tuning
[11] Christiano, P. F., et al. (2017). Deep Reinforcement Learning from Human Preferences. arXiv:1706.03741 https://arxiv.org/abs/1706.03741
[12] Amodei, D., et al. (2016). Concrete Problems in AI Safety. arXiv:1606.06565 https://arxiv.org/abs/1606.06565
[13] Skalse, J., et al. (2022). Reward Tampering Problems and Solutions in Reinforcement Learning: A Causal Influence Diagram Perspective. arXiv:2201.03544 https://arxiv.org/abs/2201.03544
[14] Zheng, L., et al. (2024). Judging LLM-as-a-Judge with LLM Judges. arXiv:2408.06266 https://arxiv.org/abs/2408.06266
[15] Wikipedia. WYSIWYG. https://en.wikipedia.org/wiki/WYSIWYG
[16] Wikipedia. Feature learning (Representation learning). https://en.wikipedia.org/wiki/Feature_learning
[17] Wikipedia. AI slop. https://en.wikipedia.org/wiki/AI_slop
[18] Paulo Nasc. Building a Golden Dataset for AI.
[19] OpenAPI Specification (OAS 3.1). OpenAPI Initiative / Swagger. https://swagger.io/specification/
[20] Shazeer, N., et al. (2017). Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. arXiv:1701.06538 https://arxiv.org/abs/1701.06538
[21] RFTKit — Reinforcement Fine-Tuning Toolkit. GitHub repository, MIT License. Accessed Oct 13, 2025. Available at: https://github.com/beconfident-ai/beconfident-rftkit